信息來源:FreeBuf
近年來�����,互聯(lián)網(wǎng)公司中大數(shù)據(jù)平臺的建設(shè)和安全一直是熱點����。筆者計劃發(fā)兩篇文章參與一下討論�����,一篇架構(gòu)+一篇安全����。本文不依托于任何一家大廠的平臺架構(gòu),用通俗的語言介紹一下大數(shù)據(jù)平臺的整體架構(gòu)�����。
下面用兩個問題開篇:
什么是大數(shù)據(jù)平臺����?是將互聯(lián)網(wǎng)產(chǎn)品和后臺的大數(shù)據(jù)系統(tǒng)整合起來����,將應(yīng)用系統(tǒng)產(chǎn)生的數(shù)據(jù)導(dǎo)入大數(shù)據(jù)平臺,經(jīng)過計算后導(dǎo)出給應(yīng)用系統(tǒng)使用。
為什么大數(shù)據(jù)平臺在互聯(lián)網(wǎng)行業(yè)非常重要����?大數(shù)據(jù)平臺將互聯(lián)網(wǎng)應(yīng)用和大數(shù)據(jù)產(chǎn)品整合起來,將實時數(shù)據(jù)和離線數(shù)據(jù)打通�����,使數(shù)據(jù)可以實現(xiàn)更大規(guī)模的關(guān)聯(lián)計算����,挖掘出數(shù)據(jù)更大的價值,從而實現(xiàn)數(shù)據(jù)驅(qū)動業(yè)務(wù)����。大數(shù)據(jù)平臺使得大數(shù)據(jù)技術(shù)產(chǎn)品可以落地應(yīng)用,實現(xiàn)了自身價值�����。
總體來說:大數(shù)據(jù)平臺可以分為四個部分:數(shù)據(jù)采集�����、數(shù)據(jù)處理�����、數(shù)據(jù)輸出和任務(wù)調(diào)度管理。
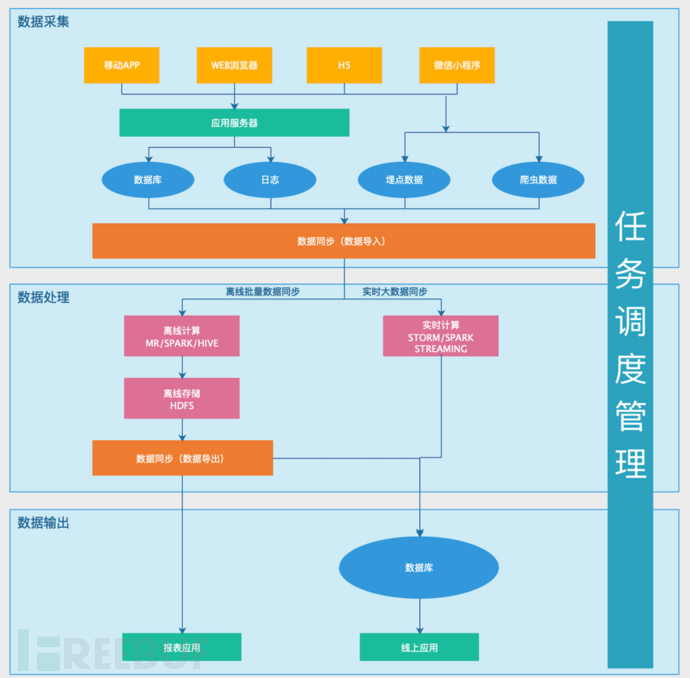
一�����、數(shù)據(jù)采集
按照數(shù)據(jù)源可以分為如下4點:
1�����、數(shù)據(jù)庫數(shù)據(jù)
目前比較常用的數(shù)據(jù)庫導(dǎo)入工具有Sqoop和Canal����。
Sqoop 是一個數(shù)據(jù)庫批量導(dǎo)入導(dǎo)出工具,可以將關(guān)系數(shù)據(jù)庫的數(shù)據(jù)批量導(dǎo)入到 Hadoop�����,也可以將 Hadoop 的數(shù)據(jù)導(dǎo)出到關(guān)系數(shù)據(jù)庫�����。
Sqoop 適合關(guān)系數(shù)據(jù)庫數(shù)據(jù)的批量導(dǎo)入�����,如果想實時導(dǎo)入關(guān)系數(shù)據(jù)庫的數(shù)據(jù)�����,可以選擇Canal����。Canal是阿里巴巴開源的一個 MySQLbinlog 獲取工具,binlog 是 MySQL 的事務(wù)日志����,可用于MySQL數(shù)據(jù)庫主從復(fù)制,Canal 將自己偽裝成 MySQL 從庫����,從 MySQL 獲取binlog。
2�����、日志數(shù)據(jù)
日志是大數(shù)據(jù)平臺重要數(shù)據(jù)來源之一����,應(yīng)用程序日志一方面記錄各種程序執(zhí)行狀況,一方面記錄用戶的操作軌跡�����。Flume 是大數(shù)據(jù)日志收集常用的工具。Flume 最早由 Cloudera 開發(fā)����,后來捐贈給 Apache 基金會作為開源項目運營。
3����、前端程序埋點
所謂前端埋點,是應(yīng)用前端為了進行數(shù)據(jù)統(tǒng)計和分析采集數(shù)據(jù)�����。
用戶的某些前端行為并不會產(chǎn)生后端請求�����,比如用戶頁面停留時間����、用戶瀏覽速度、用戶點選又取消等等�����。這些信息對于分析用戶行為等都很有價值。但是這些數(shù)據(jù)必須通過前端埋點獲得�����,有些互聯(lián)網(wǎng)公司會將前端埋點數(shù)據(jù)當(dāng)作最主要的大數(shù)據(jù)來源����,用戶所有前端行為����,都會埋點采集,再輔助結(jié)合其他的數(shù)據(jù)源����,構(gòu)建自己的大數(shù)據(jù)倉庫,進而進行數(shù)據(jù)分析和挖掘����。
對于一個互聯(lián)網(wǎng)應(yīng)用,當(dāng)我們提到前端的時候�����,可能指的是如下幾類:
(1)App 程序����,比如一個 iOS 應(yīng)用或者 Android 應(yīng)用����,安裝在用戶的手機或者平板上����;
(2)PC Web 前端,使用 PC 瀏覽器打開�����;
(3)H5 前端����,由移動設(shè)備瀏覽器打開;
(4)微信小程序�����,在微信內(nèi)打開����。
這些不同的前端使用不同的開發(fā)語言開發(fā),運行在不同的設(shè)備上����,每一類前端都需要解決自己的埋點問題����。
埋點的方式主要有手工埋點�����、自動化埋點和可視化埋點����。
手工埋點就是前端開發(fā)者手動編程將需要采集的前端數(shù)據(jù)發(fā)送到后端的數(shù)據(jù)采集系統(tǒng)����。通常公司會開發(fā)一些前端數(shù)據(jù)上報的 SDK,前端工程師在需要埋點的地方����,調(diào)用 SDK,按照接口規(guī)范傳入相關(guān)參數(shù)�����,比如 ID����、名稱�����、頁面�����、控件等通用參數(shù)�����,還有業(yè)務(wù)邏輯數(shù)據(jù)等�����,SDK 將這些數(shù)據(jù)通過 HTTP 的方式發(fā)送到后端服務(wù)器����。
自動化埋點則是通過一個前端程序 SDK����,自動收集全部用戶操作事件,然后全量上傳到后端服器。自動化埋點有時候也被稱作無埋點����,意思是無需埋點,實際上是全埋點����,即全部用戶操作都埋點采集。自動化埋點的好處是開發(fā)工作量小�����,數(shù)據(jù)規(guī)范統(tǒng)一�����。缺點是采集的數(shù)據(jù)量大����,很多數(shù)據(jù)采集來也不知道有什么用����,白白浪費了計算資源,特別是對于流量敏感的移動端用戶而言����,因為自動化埋點采集上傳花費了大量的流量�����,可能因此成為卸載應(yīng)用的理由�����,這樣就得不償失了�����。在實踐中�����,有時候只是針對部分用戶做自動埋點�����,抽樣一部分數(shù)據(jù)做統(tǒng)計分析����。
介于手工埋點和自動化埋點之間的����,還有一種方案是可視化埋點����。通過可視化的方式配置哪些前端操作需要埋點�����,根據(jù)配置采集數(shù)據(jù)����。可視化埋點實際上是可以人工干預(yù)的自動化埋點�����。
4����、爬蟲系統(tǒng)
通過網(wǎng)絡(luò)爬蟲獲取外部數(shù)據(jù)用于行業(yè)數(shù)據(jù)支撐����,管理決策等。由于涉及到敏感內(nèi)容����,不做更多的展開�����。
二����、數(shù)據(jù)處理
大數(shù)據(jù)平臺的核心�����,分為離線計算和實時計算兩類�����。
1�����、離線計算
由MapReduce�����、Hive�����、Spark 等進行的計算處理。
2����、實時計算
由Storm、SparkSteaming 等流式大數(shù)據(jù)引擎完成����,可以在秒級甚至毫秒級時間內(nèi)完成計算。
三�����、數(shù)據(jù)輸出
大數(shù)據(jù)處理與計算產(chǎn)生的數(shù)據(jù)寫入到 HDFS 中�����,但應(yīng)用程序不會到 HDFS 中讀取數(shù)據(jù)�����,所以必須要將 HDFS 中的數(shù)據(jù)導(dǎo)出到數(shù)據(jù)庫中����。除了給用戶提供數(shù)據(jù),大數(shù)據(jù)平臺還需要在一些后臺系統(tǒng)中給運營和決策層提供各種統(tǒng)計數(shù)據(jù)�����,這些數(shù)據(jù)也寫入數(shù)據(jù)庫�����,被相應(yīng)的后臺系統(tǒng)訪問�����。
四����、任務(wù)調(diào)度管理
將上面三個部分有效整合和運轉(zhuǎn)起來的是任務(wù)調(diào)度管理系統(tǒng),它的主要作用是:
(1)合理調(diào)度各種 MapReduce����、Spark 任務(wù)使資源利用最合理
(2)盡快執(zhí)行臨時的重要任務(wù)
(3)對作業(yè)提交、進度跟蹤����、數(shù)據(jù)查看等功能
簡單的大數(shù)據(jù)平臺任務(wù)調(diào)度管理系統(tǒng)其實就是一個類似 Crontab 的定時任務(wù)系統(tǒng),按預(yù)設(shè)時間啟動不同的大數(shù)據(jù)作業(yè)腳本����。復(fù)雜的大數(shù)據(jù)平臺任務(wù)調(diào)度還要考慮不同作業(yè)之間的依賴關(guān)系����。開源的大數(shù)據(jù)調(diào)度系統(tǒng)有 Oozie�����,也可以在此基礎(chǔ)進行擴展����。